












 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


手把手教你实现神经网络
更新时间:2021年03月10日17时52分 来源:传智教育 浏览次数:
在这篇文章中,我们将从头开始实现一个简单的3层神经网络。假设你熟悉基本的微积分和机器学习概念,例如:知道什么是分类和正规化。理想情况下,您还可以了解梯度下降等优化技术的工作原理。 但是为什么要从头开始实施神经网络呢?它可以帮助我们了解神经网络的工作原理,这对于设计有效模型至关重要。
1.1 生成数据集
这里我们首先生成后面要用的数据集。生成数据集可以使用scikit-learn (http://scikit-learn.org/)里面的make_moons (http://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_moons.html)函数。
In [1]:
# 导包
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.linear_model
import matplotlib
# 设置matplot参数
%matplotlib inline
matplotlib.rcParams['figure.figsize'] = (10.0, 8.0)
In [2]:
# 生成数据集并用plot画出
np.random.seed(0)
X, y = sklearn.datasets.make_moons(200, noise=0.20)
plt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.Spectral)
Out[2]:
<matplotlib.collections.PathCollection at 0x1a1ee64f60>
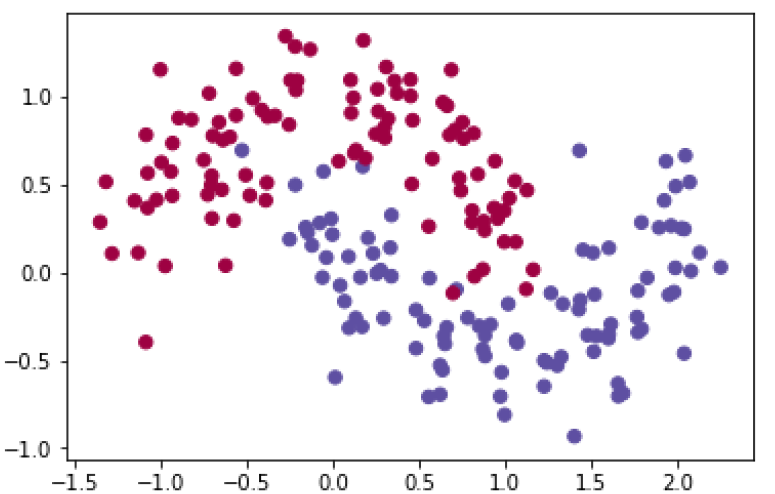
这个数据集有两个类别,分别是用红色和蓝色表示。我们的目标是使用机器学习的分类器根据x, y坐标预测出正确的类别。注意这里的数据并不是线性可分的。我们不能画一条直线把这个数据集分成两个类别。这就意味着,线性分类器,比如逻辑回归无法对我们的数据行拟合,换言之就是无法用线性分类器对这个数据集行分类。除非手动构造非线性特征,比如多项式。事实上这正是神经网络的主要优点之一。使用神经网络我们不用去做特征工程 (http://machinelearningmastery.com/discover-feature-engineering-how-to-engineerfeatures-and-how-to-get-good-at-it/)。神经网络的隐藏层会自动的学习这些特征。
1.2 逻辑回归
这里为了演示,我们使用逻辑回归行分类。输入是数据集里的x, y坐标,输出是预测的类别(0或者1)。为了方便我们直接使用scikit-learn 中的逻辑回归。
In [3]:
# 训练逻辑回归分类器
clf = sklearn.linear_model.LogisticRegressionCV(cv=5)
clf.fit(X, y)
Out[3]:
LogisticRegressionCV(Cs=10, class_weight=None, cv=5, dual=False, fit_intercept=True, intercept_scaling=1.0, max_iter=100, multi_class='warn', n_jobs=None, penalty='l2', random_state=None, refit=True, scoring=None, solver='lbfgs', tol=0.0001, verbose=0)
In [4]:
# 这是个帮助函数,这个函数的作用是用来画决策边界的,如果看不懂函数内容不用介意。
def plot_decision_boundary(pred_func):
# 设置边界最大最小值
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# 生成一个点间网格,它们之间的距离为h
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 预测
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制轮廓和训练示例
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
In [5]:
plot_decision_boundary(lambda x: clf.predict(x))
plt.title("Logistic Regression")
Out[5]: Text(0.5, 1.0, 'Logistic Regression')
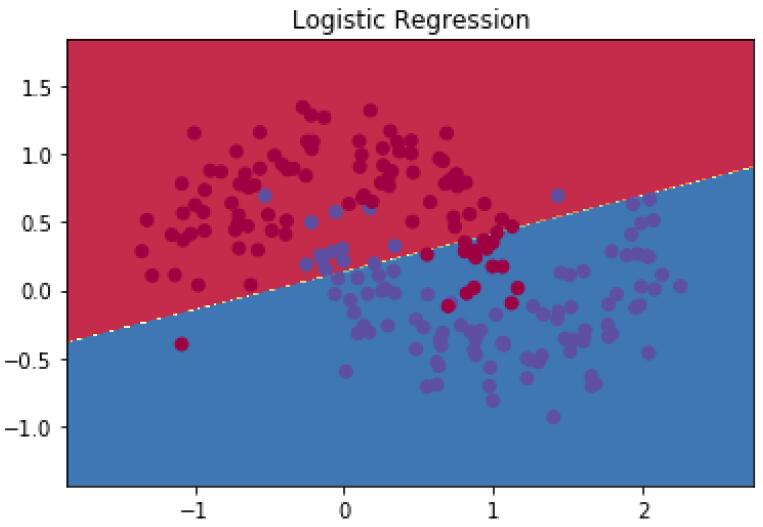
这个图显示了通过逻辑回归学习到的决策边界。这里的直线已经尽可能的把数据集分成两部分,但是分的效果还是不理想,还是有些分错类别的。
1.3 训练神经网络
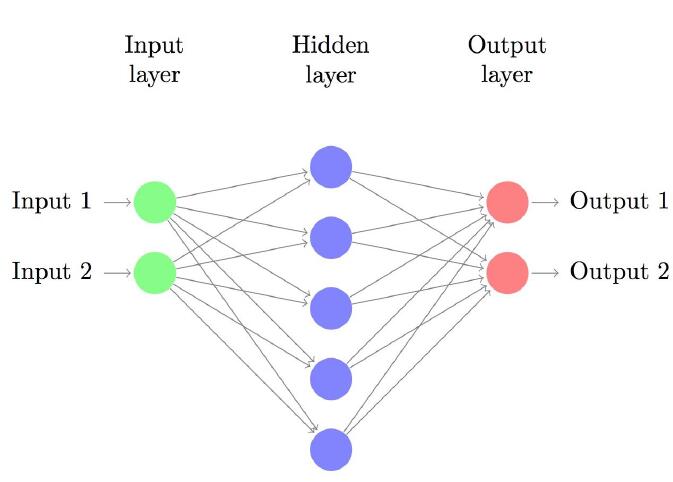
现在我们构建一个3层神经网络,其中包含一个输入层,一个隐藏层和一个输出层。输入层中的节点数由我们的数据的维数确定的,这里是2。输出层中的节点数由我们拥有的类别数量决定,这里也是2。因为我们只有两个类 实际上只用一个输出节点可以预测0或1,但是有两个可以让网络更容易扩展到更多的类。 网络的输入将是x和y坐标,其输出将是两个概率,一个用于类别0,一个用于类别1。 神经网络如图所示:
我们可以选择隐藏层的维度也就是节点数。隐藏层的节点越多,得到的神经网络功能就越复杂。但更高的维度需要付出代价。首先,学习网络参数和预测就需要更多的计算量。同时更多参数也意味着我们得到的模型更容易过拟合。 如何选择隐藏层的大小?虽然有一些指导方针,但实际上具体问题需要具体分析,稍后我们将改变隐藏层中的节点数量来查看它如何影响我们的输出。

因为我们希望神经网络最终输出概率值,所以输出层的激活函数使用softmax(https://en.wikipedia.org/wiki/Softmax_function)这只是将原始分数转换为概率的一种方法。同时如果熟悉逻辑函数,可以认为softmax可以做多分类。
1.3.2 参数学习


1.3.3 实现代码
现在我们把具体代码实现来,这里先定义一些后面求梯度会用到的参数:
In [6]:
num_examples = len(X) # 训练集大小
nn_input_dim = 2 # 输入层维度
nn_output_dim = 2 # 输出层维度
# 梯度下降参数,这两个参数是⼈为设定的超参数
epsilon = 0.01 # 梯度下降的学习率
reg_lambda = 0.01 # 正则化强度
首先我们实现上面定义的损失函数,这里用它来评估我们的模型的好坏:
In [7]:
# 帮助函数用来评估数据集上的总体损失
def calculate_loss(model):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 前向传播来计算预测值
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 计算损失值
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
# 为损失添加正则化
data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
return 1./num_examples * data_loss
这里实现了一个帮助函数来计算网络的输出。它按照上面的定义行前向传播,并返回具有最高概率的类别。
In [8]:
# 帮助函数用来预测输出类别(0或者1)
def predict(model, x):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 前向传播
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)
最后这个函数是训练神经网络。这个函数李我们用前面定义的的反向传播导数实现批量梯度下降。
In [9]:
# 这个函数学习神经网络的参数并返回模型。
# - nn_hdim: 隐藏层中的节点数
# - num_passes: 通过梯度下降的训练数据的次数
# - print_loss: 如果为True,则每1000次迭代打印一次损失值
def build_model(nn_hdim, num_passes=20000, print_loss=False):
# 将参数初始化为随机值。模型会学习这些参数。
np.random.seed(0)
W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, nn_output_dim))
# 这个是最终返回的值
model = {}
# 梯度递降
for i in range(0, num_passes):
# 前向传播
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 反向传播
delta3 = probs
delta3[range(num_examples), y] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(X.T, delta2)
db1 = np.sum(delta2, axis=0)
# 添加正则化项(b1和b2没有正则化项)
dW2 += reg_lambda * W2
dW1 += reg_lambda * W1
# 梯度下降参数更新
W1 += -epsilon * dW1
b1 += -epsilon * db1
W2 += -epsilon * dW2
b2 += -epsilon * db2
# 为模型分配新参数
model = {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
# 选择打印损失,这个操作开销很大,因为它使用整个数据集,所以不要频繁做这个操作。
if print_loss and i % 1000 == 0:
print("Loss after iteration %i: %f" % (i, calculate_loss(model)))
return model
1.3.4 隐藏层大小为3的神经网络
下面来看看如果我们训练隐藏层大小为3的网络会发生什么。
In [10]:
# 隐藏层大小为3
model = build_model(3, print_loss=True)
# 绘制决策边界
plot_decision_boundary(lambda x: predict(model, x))
plt.title("Decision Boundary for hidden layer size 3")
Loss after iteration 0: 0.432387
Loss after iteration 1000: 0.068947
Loss after iteration 2000: 0.068901
Loss after iteration 3000: 0.071218
Loss after iteration 4000: 0.071253
Loss after iteration 5000: 0.071278
Loss after iteration 6000: 0.071293
Loss after iteration 7000: 0.071303
Loss after iteration 8000: 0.071308
Loss after iteration 9000: 0.071312
Loss after iteration 10000: 0.071314
Loss after iteration 11000: 0.071315
Loss after iteration 12000: 0.071315
Loss after iteration 13000: 0.071316
Loss after iteration 14000: 0.071316
Loss after iteration 15000: 0.071316
Loss after iteration 16000: 0.071316
Loss after iteration 17000: 0.071316
Loss after iteration 18000: 0.071316
Loss after iteration 19000: 0.071316
Out[10]: Text(0.5, 1.0, 'Decision Boundary for hidden layer size 3')
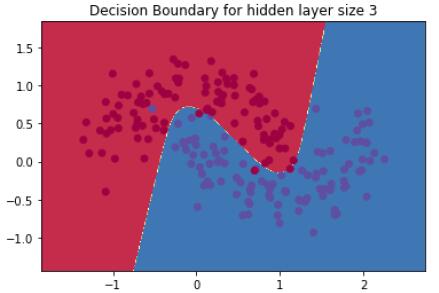
这看起来很不错。我们的神经网络能够找到一个成功分离两个类别的决策边界。
2 改变隐藏的图层大小
在上面的示例中,我们设置了隐藏层大小3,接着看看改变隐藏层大小对结果的影响。
In [11]:
plt.figure(figsize=(16, 32))
hidden_layer_dimensions = [1, 2, 3, 4, 5, 20, 50]
for i, nn_hdim in enumerate(hidden_layer_dimensions):
plt.subplot(5, 2, i+1)
plt.title('Hidden Layer size %d' % nn_hdim)
model = build_model(nn_hdim)
plot_decision_boundary(lambda x: predict(model, x))
plt.show()
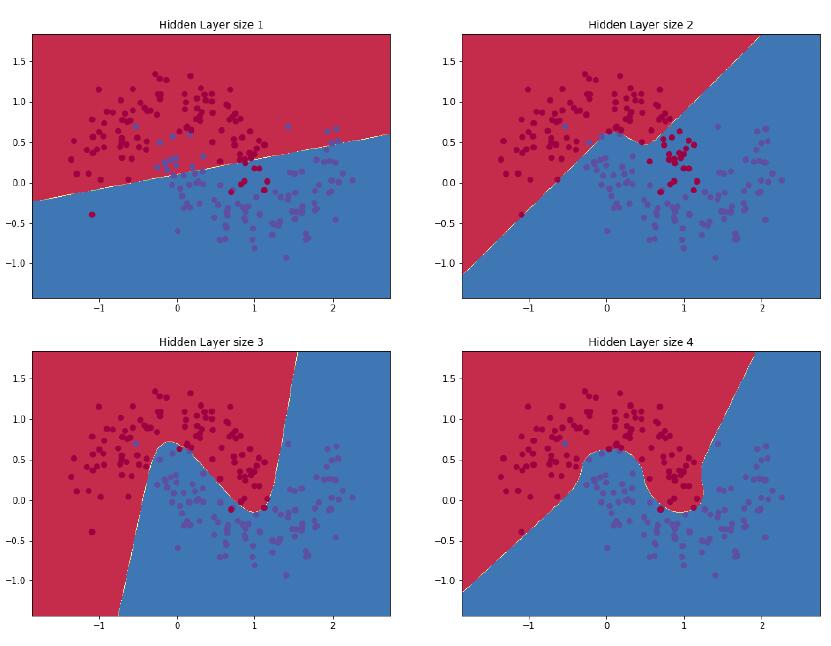
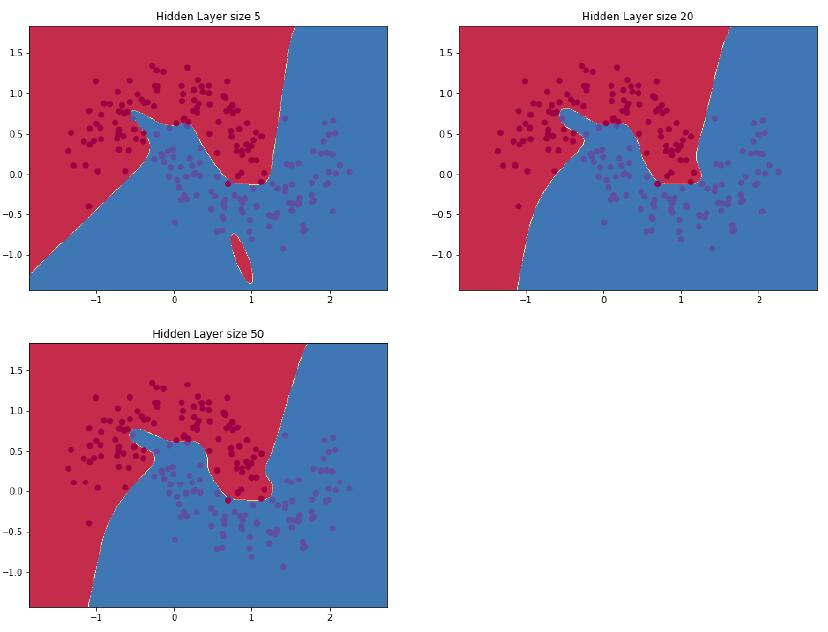
我们可以看到,隐藏层在低维度时可以很好地拟合数据的总体趋势,更高的维度容易过拟合。当隐藏层维度过大时,模型尝试着去“记住”数据的形状而不是拟合他们的一般形状。通常情况我们还需要一个单独的测试集来评估我们的模型,隐藏层维度较小的模型在这个测试集上的表现应该更好,因为这个模型更加通用。我们也可以通过更强的正则化来抵消过度拟合,但是选择一个合适的隐藏层大小是一个比较划算的解决方案。
猜你喜欢
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
